

Agile se trata de mejora y aprendizaje continuo, al final uno de los doce principios de agilidad señala que “At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.”.
Scrum, principal framework de Agilidad, se basa igualmente en el proceso empírico de “Transparencia, Inspección y Adaptación”, lo que señala que la forma correcta de desarrollar a través de este marco de trabajo es a través de la inspección de datos y la adaptación a través de la información que se genere mediante ellos.
La planeación de los releases tiende a tener un reto importante: estimar o conocer cual es la velocidad del equipo. La velocidad (Velocity, en inglés) es la cantidad de puntos o esfuerzo que un equipo puede atacar dentro de cada iteración fn-1. Es importante siempre convenir en un rango de Velocidad y no en un número cerrado para esto, ya que es muy probable que el número no se cumpla de forma exacta siempre.
La forma habitual de calcular este rango es a través de los valores históricos (al final, estamos aplicando el proceso empírico) pero siempre que desarrollo proyectos ágiles con algún cliente o mis colaboradores, en la primera iteración me suelen consultar lo mismo siempre:
¿Y qué valor ponemos en la Velocidad siendo esta la primera iteración y no teniendo valores históricos?
Esta siempre es una excelente pregunta, ya que al ser la primera iteración es imposible dar con un valor que esté fundamentado en la experiencia previa. Es por ello que el cálculo de la velocidad puede desarrollarse a través de una de las siguientes formas siempre:
- Hacer una estimación en base a pronóstico.
- Hacer una iteración y utilizar el valor generado.
Cada método tiene sus ventajas (y desventajas) y aun más importante: cada método funciona mejor bajo algunos criterios. Veamos más a fondo cada uno de ellos.
#.1. Estimación en base a un pronóstico
Este método es usualmente el método correcto para la primera iteración, ya que no se poseen datos históricos de referencia dentro de los cuales se puedan “referenciar” o evaluar las velocidades. Este método es igualmente funcional cuando el grado de incertidumbre es demasiado alto.
La manera más habitual conlleva un proceso secuencial similar al siguiente:
- Cada historia de usuario inicial se desglosa en distintas tareas.
- Ir introduciendo las historias (idealmente desglosadas en tareas independientes estimadas) a una iteración.
- Consultar al equipo si consideran que pueden atacar esta cantidad de esfuerzo.
Se repite este proceso hasta que el equipo considere que no puede atacar más historias dentro de la iteración o hasta que el equipo considere que solo se puede comprometer a lo que está asignado a la iteración.
#.Focus time (o tiempo de enfoque)
Otra alternativa de este método muy utilizado es el de estimar en base a una conversión de tiempo-esfuerzo (aun contrario a algunas teorías de estimación). Para ello regularmente se realizan de forma paralela algunos cálculos.
Primero, debemos hacer una relación “aproximada” (rough) entre los puntos de esfuerzo y las horas. Posteriormente debemos hacer una tabla con algunos cálculos por cada uno de los miembros del equipo:
- Cantidad de horas disponibles dentro de la iteración.
- Porcentaje de enfoque.
- Total de horas de enfoque (Cantidad de horas * Porcentaje de enfoque / 100).
El porcentaje de enfoque está relacionado con diversos estudios que demuestran que una persona que dedica el 100% de su tiempo en un proyecto solo enfoca entre 55-70% en producir para el proyecto fn-2 fn-3.
En lo particular, no recuerdo si en algún lugar leí que a este valor le referenciaban como porcentaje de enfoque, pero es el término que utilizo personalmente para llamar a este valor. Luego de varios años realizando mediciones sobre este valor, he notado que el mismo suele estar por el 60% y usualmente este porcentaje suele ser menor al inicio del proyecto y suele subir cuando el equipo ya se encuentra más “cómodo” en el proyecto.
Habiendo calculado el total de “horas de enfoque”, procedemos a sumar la cantidad de horas y lo multiplicamos por la relación “aproximada” de esfuerzo-horas para saber la cantidad de puntos que puede nuestro equipo atender (tomando en consideración la duración del Sprint).
Analicémoslo con un ejemplo:
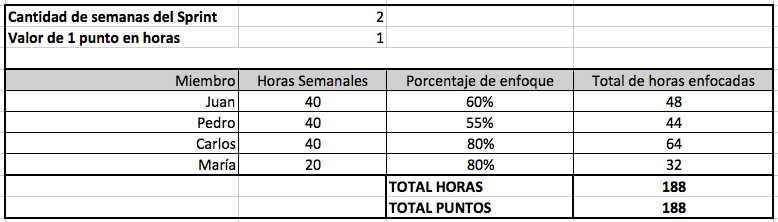
En el ejemplo anterior, tenemos a 4 personas dentro del Dev Team, para una iteración de 2 semanas y una relación de 1:1 entre horas y puntos de esfuerzo. Cada miembro del equipo se esfuerza en 40 horas cada semana, menos María quien está asignada al proyecto solo 20 horas; lo sé, lo sé … en teoría debería estar asignada únicamente al proyecto, pero en la vida real no siempre pasa.
Cada persona tiene un porcentaje de enfoque distinto. Como Pedro es el Junior del equipo, le ponemos un enfoque menor. Carlos, a diferencia, es el que más conocimientos tiene sobre la tecnología y el proyecto. María, al estar asignada poco tiempo en el proyecto y tiene poca incertidumbre en sus tareas, tiene un porcentaje de enfoque superior.
Para cada uno de ellos debemos hacer el siguiente cálculo:
Total de horas enfocadas = Horas semanales * Cantidad de semanas del Sprint * Porcentaje de enfoque / 100Al final, sumamos el Total de Horas Enfocadas y lo multiplicamos por la relación entre horas-esfuerzo (o el valor de 1 punto en horas) y esto nos da una Velocidad pronosticada para la siguiente iteración. En el caso anterior, podríamos decir que la Velocidad estaría entre 180-190.
Usualmente utilizo este formato durante la primera iteración o si el equipo se le dificulta un poco trabajar con story points inicialmente (o si la rotación del equipo es muy alta).
#.2. Iteración y valor generado
Esta para mi es la forma más habitual y correcta de medir la velocidad y se puede utilizar en conjunto con el primer método (pasada la primera iteración). En mi concepto esta es la que debe prevalecer sobre cualquier otra puesto que:
- Se están utilizando datos reales para la toma de decisión.
- El valor tiende a ser realista (y certero).
- La mejor forma de predecir la velocidad es evaluando la velocidad.
Para desarrollar este método debemos ejecutar una serie de iteraciones y medir los puntos que fueron atendidos por iteración. Usualmente se puede comenzar con tres o más iteraciones, ya que esta cantidad de iteraciones permite evaluar si hay una cantidad estable de puntos atendidos.
Digamos que hacemos el ejercicio con 4 iteraciones y las mismas generan los siguientes resultados:
- Iteración 1: 14 puntos
- Iteración 2: 12 puntos
- Iteración 3: 16 puntos
- Iteración 4: 14 puntos
Podemos establecer el rango de velocidad entre 12 (mínimo) y 16 (máximo) puntos en base a nuestra experiencia.
#.Comentarios finales
Como comentarios finales quiero aclarar que la estimación de la velocidad sigue siendo una estimación y no un valor estable ni tampoco un valor que se pueda poner en piedra. Además de estos dos métodos, pueden utilizarse siempre valores de proyectos pasados pero esto usualmente no es factible a menos que sea el mismo equipo, sea el mismo tipo de proyecto (mismo fin, mismas tecnologías) y muchas variables del proyecto se mantengan. Algo que es casi imposible que ocurra en proyectos y menos de software.
Al hablar de estimaciones siempre surge útil hablar sobre el “Cono de la Incertidumbre” fn-4 que describe como la incertidumbre (como un rango) en un proyecto se reduce a medida que el proyecto avanza y el equipo evoluciona.
Leí el concepto explicado en Agile por primera vez a Mike Cohn, en su libro “Agile Estimating and Planning”, donde (a diferencia para lo explicado por el PMI) hacía referencia a los estudios de Barry Boehm (1981) en donde detalló un rango de incertidumbre entre 0.6x y 1.6x:
The cone of uncertainty shows that during the feasibility phase of a project a schedule estimate is typically as far off as 60% to 160%. That is, a project expected to take 20 weeks could take anywhere from 12 to 32 weeks.
Este rango de valores se reduce conforme el tiempo pasa, según puede evaluarse en la siguiente gráfica:
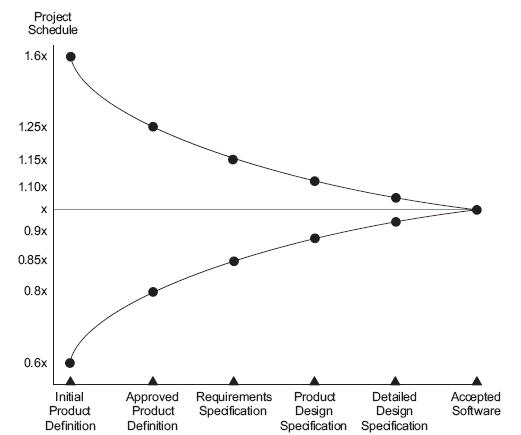
Esto quiere decir que, conforme pase el tiempo, las estimaciones también llegan a reducir la incertidumbre y cada vez lograrán ser más reales. Esto es aplicable tanto para las estimaciones de puntos como para las estimaciones de velocidad.
- https://www.agilealliance.org/glossary/velocity/.↩
- BOEHM, Barry (1981). “Software Engineering Economics”.↩
- GANSSLE, Jack (2004). “Embedded Systems Programming”.↩
- https://es.wikipedia.org/wiki/Cono_de_incertidumbre.↩